



Dans une optique de publication omnicanale automatisée, le traitement et la validation du contenu à publier (texte, images, vidéos, etc.) deviennent laborieux et sujets à erreurs, sans un outil dédié.
Pour traiter efficacement le contenu, il faut d’abord le comprendre, donc le structurer.
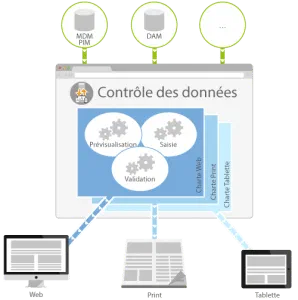
L’être humain peut, de façon quasi-naturelle, identifier sans effort particulier les différentes entités d’information présentes dans un flux de données. Les logiciels utilisés dans le monde professionnel de l’éditique n’ont pas encore cette capacité. Les méta-données permettent ainsi de donner un sens formel aux entités d’information auxquelles elles sont rattachées de façon à pouvoir les identifier et leur appliquer des traitements, que ce soit dans une optique d’échange d’information ou de mise en forme.
La structuration de l’information s’effectue généralement dans des logiciels de type CMS (Content Management System) ou PIM (Product Information Management) dont l’un des objectifs est de gérer l’information indépendamment des supports dans lesquels elle sera exploitée. Les documentalistes isolent généralement les informations de type « auteur », « titre », « lieu »… dans articles de presse ; les chefs produits sans s’en rendre compte, saisissent le nom, le descriptif et le prix des produits dans des emplacements (champs) bien distincts.
Le niveau d’abstraction mis en place dans ces différents outils, idéal en théorie, s’accommode assez mal avec une pratique véritablement omnicanale qui requiert souvent d’adapter le contenu à la mise en scène spécifique à un support donné. En pratique, qui n’a jamais dû reformuler rapidement une phrase descriptive parce que l’espace réservé dans la mise en forme est trop limité ? Quel rédacteur n’a jamais retouché un argumentaire de vente, même légèrement, pour adapter la description à l’espace alloué au produit sur une page ?
La mise en scène sur un support a donc un impact direct sur les besoins en contenu. Il est plus pratique de parcourir les derniers kilomètres avec un véhicule léger que de faire atterrir l’avion dans son jardin. En procédant de la sorte, la mise en œuvre d’un système de publication est très rapide et peut être menée indépendamment de la mise en place d’un PIM.
Par ailleurs, les PIM/MDM sont de plus en plus utilisés comme des entrepôts de données pour agréger des produits en provenance de différents fournisseurs, qui ne seront pas nécessairement publiés. Il n’est pas rare que les e-commerçants gèrent plusieurs centaines de milliers de produits alors que leur site marchand n’en propose que quelques milliers. Il est facile d’imaginer le gain à se concentrer sur la validation des produits dans le contexte de l’opération.
C’est dans cette optique que le contrôle de la donnée à publier dans le contexte du support de communication utilisé nous semble la clé d’un processus de publication omnicanale réussi.
—
Les premières formalisations du concept de méta-données (données sur des données ou information au sujet de l’information) remontent à la Bibliothèque d’Alexandrie de l’ancienne Egypte avec les travaux de Callimachus of Cyrène [1] .
Dans le domaine de la gestion documentaire, des langages se sont développés autour de la notion de métadonnées : le SGML (langage de balisage généralisé normalisé) très utilisé dans l’édition dans les années 1980-1990 a été remplacé par le XML, une version simplifiée, ou le HTML qui associées aux feuilles de styles (CSS) permettent d’afficher du contenu sur de nombreux types d’écrans (sites web, sites mobiles, tablettes…).
Il existe des initiatives dont l’objet est d’analyser un contenu à partir de l’étude de sa forme pour en restituer sa description. Par exemple,
- Des logiciels tentent d’analyser une image pour identifier ce qu’elle représente [2] ,
- IBM avec Watson ou Google effectuent des analyses sémantiques poussées basées sur des systèmes d’ontologies pour remonter au sens de l’objet décrit.
Auteur :

R. Loubéjac
Cofondateur de J2S

[1] Cf. Lisa Baures and Ann Quade in Learning Objects : Standards, Metadata, Repositories, and LCMS, p.64. Harman, K. & Koohang, A (Eds) – 2007, Santa Rosa, California : Infoming Science Press.
[2] http://googleresearch.blogspot.fr/2014/11/a-picture-is-worth-thousand-coherent.html





